Introduction
Starbucks is one of the most successful and recognizable coffee chains globally, with over 35,000 locations spread across more than 80 countries. Its continued expansion is not merely a matter of randomly selecting locations; rather, it
follows a strategic, data-driven approach to ensure maximum profitability and operational efficiency.
Choosing the right store location is crucial because multiple factors, such as customer demographics, foot traffic, proximity to competitors, accessibility, and economic conditions, significantly impact a store’s success. Traditionally, businesses relied on manual surveys, expert intuition, and historical sales data to determine potential store locations. However, the advent of data science has transformed this decision-making process by integrating geospatial analytics, machine learning, and big data techniques.
This article explores how Starbucks leverages data science to optimize its store locations, minimize risks, and maximize revenue through predictive analytics, AI-driven decision-making, and spatial data analysis.
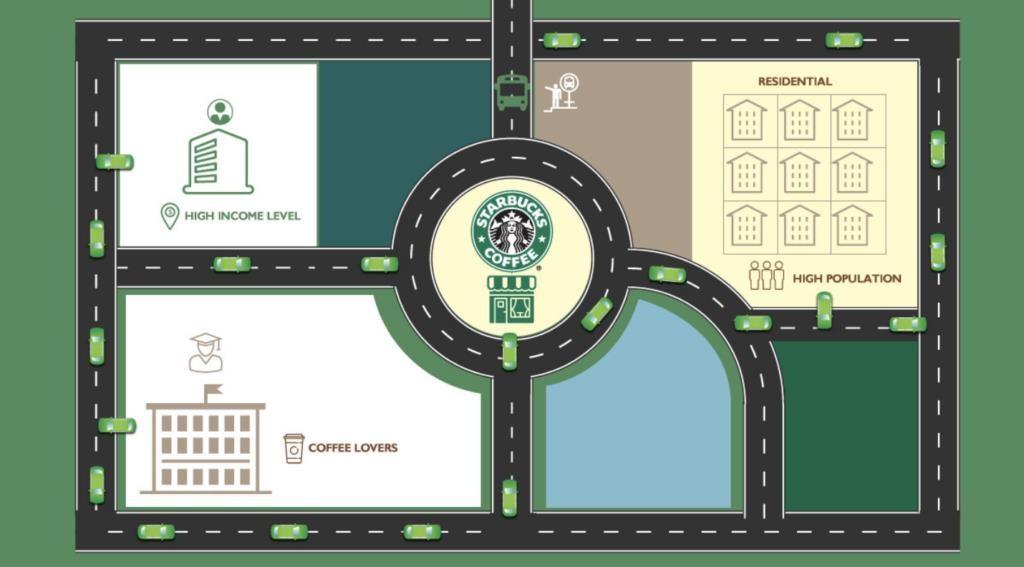
Business Challenges in Store Selection
Selecting the best location for a new Starbucks store is not a simple task. Multiple challenges must be addressed to ensure profitability and avoid business failure. Here are some key challenges Starbucks faces while selecting new store locations:
1. nderstanding Customer Demographics
One of the primary factors that influence store success is the demographic profile of the target customers in a given area. Starbucks needs to analyze factors such as:
- Age Group: Young professionals, students, and office workers tend to be key customers.
- Income Level: People with higher disposable income are more likely to purchase premium coffee regularly.
- Spending Behavior: Understanding how often customers visit coffee shops and how much they typically spend helps Starbucks estimate potential revenue.
- Population Density: A higher population in an area increases the likelihood of higher foot traffic to a store.
2. Competitor Analysis
The presence of competitors, such as Dunkin’, Costa Coffee, and local coffee shops, can impact a Starbucks store’s profitability. Starbucks analyzes competitor locations and their customer base to determine whether an area can sustain another coffee shop. It also considers:
- Market Share Analysis: How much of the local coffee market is already captured by competitors?
- Brand Loyalty: Do customers prefer competitors due to pricing, taste, or brand identity?
- Customer Overlap: Will Starbucks attract new customers or end up competing for the same audience?
3. Foot Traffic Analysis
The number of people walking past a location daily is an essential metric for selecting store locations. A high foot traffic area ensures a steady flow of potential customers. Starbucks uses:
- Pedestrian Sensors: To track movement and predict peak hours.
- Mobile Location Data: To analyze the movement patterns of customers in real time.
- Public Transportation Data: To estimate how many people travel through the area daily.
4. Real Estate Costs and Rental Viability
While high-traffic areas are attractive, the cost of leasing commercial spaces in such locations can be prohibitively high. Starbucks must balance:
- Rent-to-Revenue Ratio: Ensuring rent is proportionate to expected earnings.
- Long-Term Viability: Avoiding areas with high property price volatility.
- Economic Conditions: Analyzing whether the local economy supports sustained business growth.
5. Avoiding Market Saturation
With thousands of Starbucks locations worldwide, the company must be careful not to open stores too close to one another, leading to self-competition (cannibalization). Data science helps Starbucks assess the:
- Impact on Nearby Stores: Will the new store take business away from an existing one?
- Customer Demand: Is there enough demand to support multiple stores in the same area?
- Operational Efficiency: Can logistics, supply chains, and workforce be optimized in clustered locations?
6. Adapting to Changing Consumer Preferences
The coffee industry is evolving with trends such as:
- Mobile Ordering and Drive-Thru Demand: More customers prefer convenience-based options.
- Sustainability Preferences: More consumers are looking for eco-friendly coffee brands.
- Healthier Choices: Demand for alternative milk options and lower-calorie beverages.
Starbucks must account for these evolving preferences when choosing store locations to ensure long-term success.
How Data Science Helps Starbucks Find the Best Locations
To address these challenges, Starbucks applies a comprehensive data science approach that includes data collection, preprocessing, predictive modeling, and geospatial analytics.
Data Collection
Starbucks collects vast amounts of data from various sources, including:
- Demographic Data: Population age, income levels, and employment status.
- Customer Behavior Data: Purchase frequency, preferred beverages, and seasonal demand fluctuations.
- Geospatial Data: Pedestrian and vehicle traffic patterns, nearby businesses, and zoning regulations.
- Competitor Data: Locations, pricing strategies, and market positioning of rival coffee shops.
- Weather Data: Analyzing how climate influences coffee sales.
Data Preprocessing and Cleaning
Before analysis, Starbucks ensures that data is cleaned and prepared. This involves:
- Handling Missing Values: Filling in data gaps using statistical techniques.
- Removing Outliers: Eliminating extreme values that distort location predictions.
- Feature Engineering: Creating new variables that enhance predictive models.
- Encoding Categorical Data: Converting text-based information (e.g., city names) into numerical formats.
Predictive Modeling for Location Selection
Machine learning models predict the success of new locations based on historical data. Regression Models Used to estimate potential revenue:
- Linear Regression: Predicts sales based on foot traffic and income levels.
- Multivariate Regression: Analyzes multiple factors for accurate revenue forecasts.
Clustering Algorithms Used to segment locations based on potential profitability:
- K-Means Clustering: Groups areas into high-potential and low-potential zones.
- Hierarchical Clustering: Identifies neighborhoods with similar consumer behaviors.
Classification Models Used to categorize locations as ‘high potential’ or ‘low potential’:
- Decision Trees: Evaluates multiple factors to rank location suitability.
- Random Forest: Uses ensemble learning to improve accuracy.
- Support Vector Machines (SVM): Enhances location classification.
- Geospatial Analytics: Geographic Information Systems (GIS) help Starbucks visualize location data and optimize store placement.
- Heatmaps: Identify customer-dense areas.
- Proximity Analysis: Calculate the impact of nearby competitors.
- Drive-Time Analysis: Estimate accessibility for customers traveling by car.
2. Sentiment Analysis: Using Natural Language Processing (NLP), Starbucks analyzes:
- Social Media Mentions: Understanding local customer perceptions.
- Online Reviews: Identifying positive and negative factors affecting sales.
- Brand Sentiment in Specific Regions: Evaluating community receptiveness to new stores.
Conclusion
Starbucks’ global success is largely attributed to its data-driven approach to store expansion. By leveraging machine learning models, geospatial analytics, and customer sentiment analysis, Starbucks minimizes risks and ensures high profitability.
Key Takeaways:
- Data science enables Starbucks to optimize store locations with minimal risk.
- Machine learning models predict store performance based on historical data.
- Geospatial analytics enhances site selection through mapping techniques.
- AI-driven sentiment analysis helps Starbucks understand customer preferences.
As data science continues to evolve, Starbucks will further refine its expansion strategies, ensuring precise and efficient store placement.